the question may have appeared here more often, but I am more than confused after my research on the Internet on this topic.
My goal is to create my own voice (in german).
Since I want to have a slightly “robotic” voice for Mycroft.
To get started with the topic, I watched a tutorial and came across Google Colab Notebook, which allows to train and synthesize a Tacotron 2 model. To better understand the topic, I tried to implement that. Unfortunately, the notebook used Tensorflow 1 and thus was outdated.
Also the topic with Mimic 2 and 3 confuses me a bit and I can’t really find an entry point. Can I use Mimic for my own models?
To make it easy for the first try, I decided to use an already existing voice. The voice of Glados, since it already exists as .wav files. If i am able to create a model, that works with mycroft, I will invest more time.
I sampled the .wav files down to 22050 Hz and created a transcript file.
And now I’m stuck because all the tutorials I’ve found are outdated or don’t get me anywhere.
Could someone explain me what are the necessary steps to create a voice for Mycroft? Or give me a hint which topics I have to look at?
Mimic2 is woefully out of date. Google Thorsten’s tutorials on building your own voice.
I don’t think there’s an updated mimc3 training repo yet. For now watch the videos @Thorsten does, collect your samples, then when that’s released you can try mimic3, or coqui, or…whichever suits your needs.
in the meantime I found Thorsten videos by myself and also coqui.ai.
So my training is up and running for almost 24h now.
But if I test the voice, it’s just random noise.
The noise has changed its pattern over time, but it is still not even a letter.
Is this normal at the beginning?
Sometimes yes, if you’re starting from scratch and using something like Tacotron2. If you fine-tune an existing model, or use a simpler model like VITS, you should have results more quickly.
Thank you,
right now, I’m just playing around with different models.
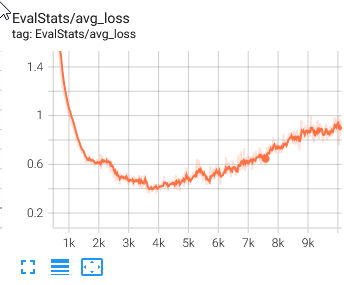
I tried glow_tts, but I had a wired thing going on where the avg loss started to increase.
Does this make any sense? Since as i understood it should go at least sideways, but never up, right?
But at least the “best” model, was not that bad as the tacotron2 model.
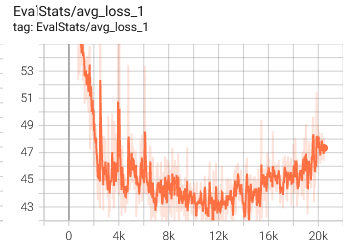
I ran a vits training overnight, and it has the same outcome:
Somewhere around 14k is the best one, but then it starts to go up.
Is this because of my dataset? Or is it just a “stage” and if i continue the training for another 1000 epochs it will get better again?
I remember Coqui TTS used to have something called “gradual training” enabled by default. This would shift the settings at specific intervals, and you’d expect to see spikes like that as it starting trying to solve a more difficult task.
I suppose this might be tricky, as this is a already synthetic voice with a lot of random pitch and formant shifts, which is unusual for human voices. Algorithms like Taco or VITS might have problems to “learn” that…
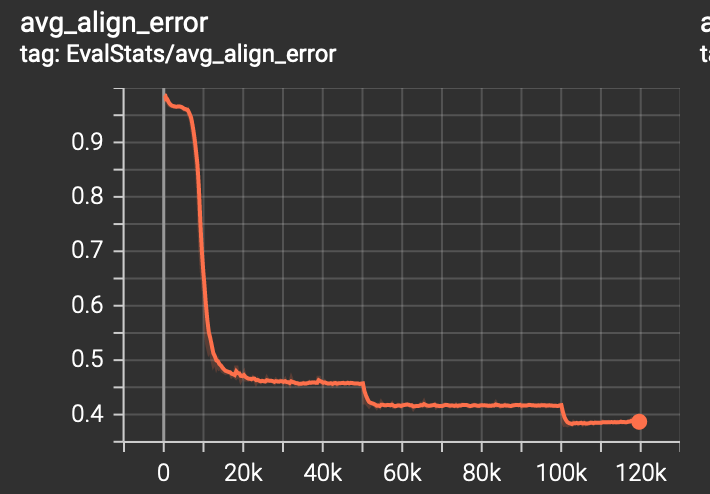
vits worked pretty good tbh. After 30k steps it was able to say a few things, and it was still learning.
But my computer restarted and now I’m unable to continue the same training, since i get a wired message when i try to run it with the --continue-path flag:
Traceback (most recent call last): File "/usr/local/lib/python3.8/dist-packages/trainer/trainer.py", line
1533, in fit self._fit() File "/usr/local/lib/python3.8/dist-packages/trainer/trainer.py", line 1521, in _fit
self.test_run() File "/usr/local/lib/python3.8/dist-packages/trainer/trainer.py", line 1439, in test_run
test_outputs = self.model.test_run(self.training_assets) File "/usr/local/lib/python3.8/dist-packages
/torch/autograd/grad_mode.py", line 28, in decorate_context return func(*args, **kwargs) File "/home
/administrator/TTS/TTS/tts/models/vits.py", line 1381, in test_run wav, alignment, _, _ = synthesis( File
"/home/administrator/TTS/TTS/tts/utils/synthesis.py", line 180, in synthesis
model.tokenizer.text_to_ids(text, language=language_id), File "/home/administrator/TTS/TTS/tts/utils
/text/tokenizer.py", line 109, in text_to_ids text = self.phonemizer.phonemize(text, separator="") File
"/home/administrator/TTS/TTS/tts/utils/text/phonemizers/base.py", line 130, in phonemize text,
punctuations = self._phonemize_preprocess(text) File "/home/administrator/TTS/TTS/tts/utils
/text/phonemizers/base.py", line 102, in _phonemize_preprocess text = text.strip() AttributeError:
'NoneType' object has no attribute 'strip'
Are there models that could fit better for a already synthetic voice?