I am using precise to train for sound that is not speech. Is it better to have one clear sample sound in the recording versus having two or more sounds (if they fit)? Enclosed is a sample to help illustrate.
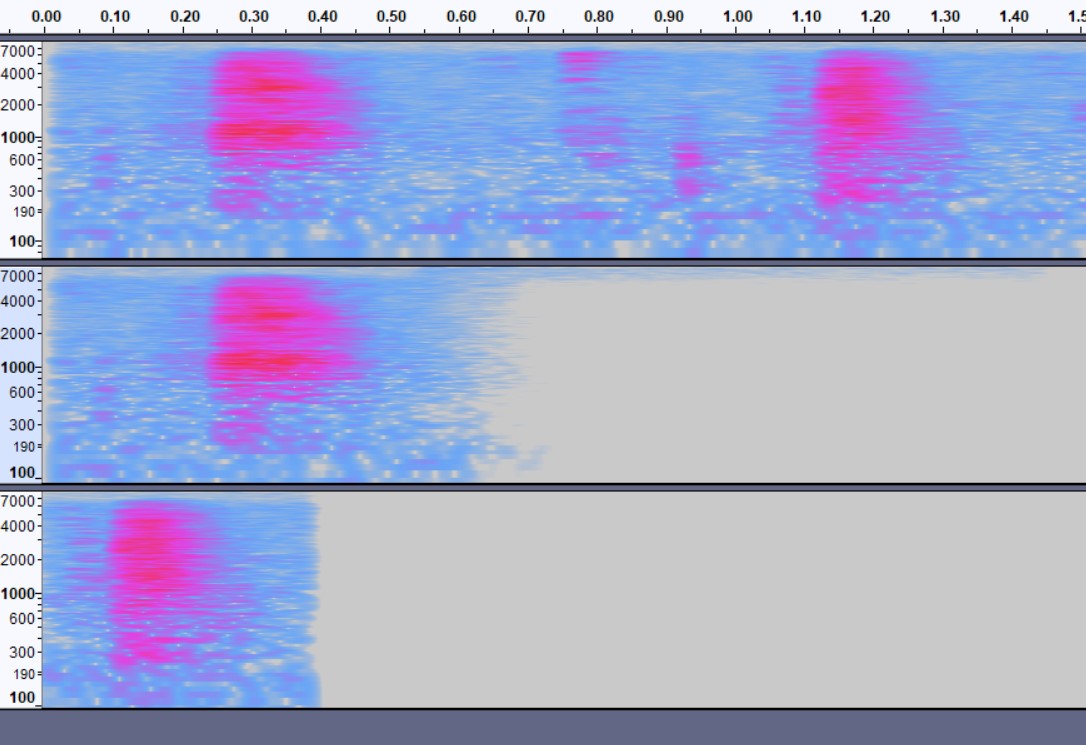
One per file is best. You want it to evaluate the sound you’re trying to trigger on, adding two will bias it towards listening for two.
great, thank you.
with the same image sample, is it okay to leave silence in the sample? as seen in the bottom two. I thought it would eliminate garbage being trained and have less negatives to train against.
Eh…I try and limit silence, but I don’t avoid it altogether. I also use a lot of saved utterances for re-training as well to improve my models. These have noise and background bumps and squeaks. The false activations are also used in the not-wake-word data, this helps quite a bit.
Yes, I am taking false pos to train as ‘not wake’, i also pass tp to retrain as ‘wake’ and do notice it helps (but before I wasn’t separating one for each as mentioned earlier, maybe now i can reach better specificity & sensitivity).
other question:
does it matter where in the 1.5 s the target sound is? the manual says it only trains on the last 1.5s, so I make them 1.5 s as safekeeping.
Not that I’ve noticed.