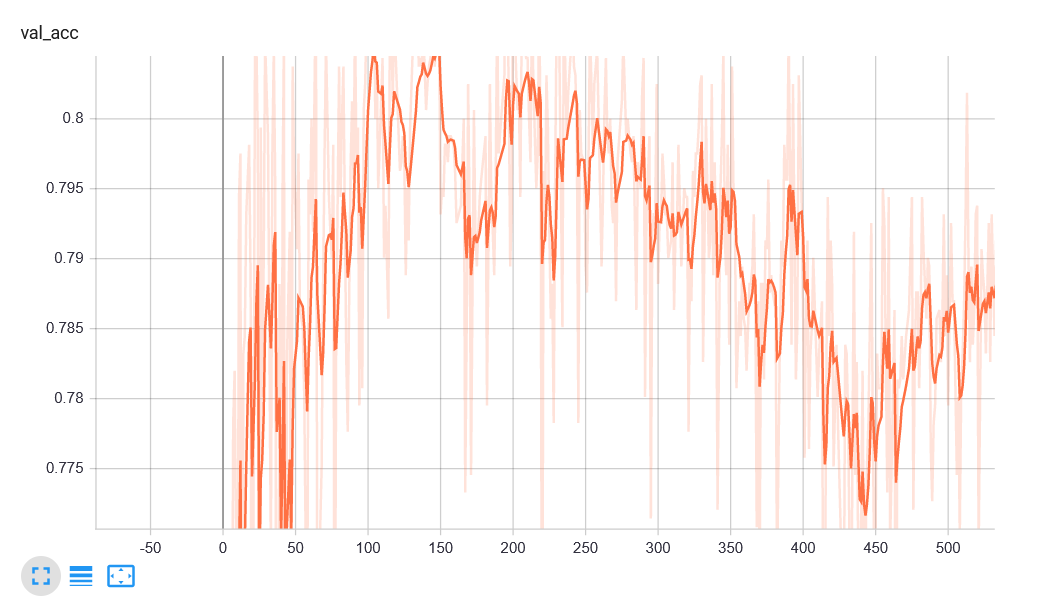
After reviewing the val_acc more carefully it seems that I might be overfitting my model, example below. Is there a way to sort of ‘roll back’ a model to a specific step without having to train again?
Also, does precise have regularization options built in? I could not locate in the docs.
For example in the following case I want to roll back and use the model on step 140.
this is for mycroft precise training custom wake sound (not speech).
There’s a save best option you can use.
is there a log that indicates which step it saved?
i think i see it in .pbtxt but you can confirm please?
Should be able to for any checkpoint
The proposed methods for training Precise and creating datasets are slightly dubious from low number of KW to just pouring large amounts of random samples to !KW.
I have been doing a lot of experimenting with google-research/kws_streaming at master · google-research/google-research · GitHub and they greatly improve accuracy by having a silence classification which at first I thought was some sort of VAD/SAD.
It add background_noise to that classification and also mixes background_noise to KW & !KW and the silence classification sort of acts as a catch_all for non voice.
KW is obviously KW and !KW the way I have been training is some sentences word split with sox.
Sox again is used to Pitch, Pad, Volume & Temp and each sample is varied into many more.
background_noise it splits and adds automatically but as a minimum I was using 1000 as for validation and testing it expects 100 and had it set at 10%
The CRNN in the kws_streaming is only a couple of % more accurate on the google_command set which is a bad benchmark dataset (deliberately so as otherwise all recent model would attain 100%) but I always gain 100% validation and overfitting just doesn’t happen.
I just dont get some of the proposed methods especially pouring in loads of random where !KW becomes heavy and out of balance with what should be the predominance of KW.
The google KWS_streaming isn’t perfect as it mixes background_noise in a arbitrary range without taking into account KW volume level as a KW is no longer a KW when the background is louder and there is a certain ratio where really there is not enough left.
So I have been making custom datasets using sox and mixing background_noise with similar KW & !KW so I can have a much greater range without painting over the original sample.
I get results that blow Precise out of the water and make its name an odd choice with high levels of input noise 70Db @ the mic with KW still recognised.
As for false positives there is no comparison as the 20ms streaming KWS creates a 50 sample envelope and its not just a single confidence level test but creates a sum of the input until I figure out a better method for envelope detection.
All the hard work has been done by Googleresearch but playing with dataset and results has been interesting and have a bit of a quick guide in my repo which is just an adaption GitHub - StuartIanNaylor/g-kws: Adaption of the Googleresearch kws repo
Also because it is also quantised tensorflow-lite it runs in less than 20% of a single core on a Pi3A+.
But irrespective of better models and lighter frameworks in TFL as opposed to the heavyweight full TF the manner of dataset collection, quantities and methods as if I do something similar I would expect to lose somewhere around 10-15% of my validation results to what I have, using what seems to be proposed.
yes, as pointed out by baconator one can use the -sb switch.
Not sure the remaining is relevant, but thank you for your details
1 Like
You may find it is from actual use results.