Wanting to try a custom wake word but not sure you can get a precise model made? Having problems getting a model built that works as expected? Just need some more data for your wake word?
Precise-Community-Data may be the place for you! It’s a place to build a community-sourced dataset, oriented specifically towards custom wake words.
For a limited time only, and for the simple price of uploading your wakewords, I’m doing automated custom builds of precise wakewords. Get your wake words and some not-wake-words uploaded, and I’ll build models for them over the following week (probably less). They’ll be automated builds based off your wakewords plus all the not-wake-word data I can use (google words, public noises archive, PCD nww’s, etc). No guarantee on the quality of the end model, they usually turn out high 90’s recognition percentage.
Feel free to post questions here, or upload data at the repo. We’re happy to start accepting more, and hope to build a much larger dataset for everyone to make better models from.
PAQ:

How many words do you need to upload?
For each wakeword at least 20. The more, the merrier.
Do you need to upload not-wake-words?
Yes…they’re at least as useful as wake words, and if you do targeted nww’s, even more so.
I don’t want to upload my voice since it might get recognized from my account, though.
Then don’t. Or make a secondary git account and upload from it. Or a tertiary one. Lots of ways to obfuscate things if you want. Most people and so far computers can’t accurately distinguish a very short sample of speech without additional context.
I don’t have a github account/know how to use git?
You should get one! The general usage isn’t too difficult. On the off chance you have some real issue with this, send me a message over on the chat system.
I don’t want to upload under public domain
there’s a couple other license types you can explore, but mainly the creative commons licenses that allow for derivative usage would be best.




 hoorah!!!
hoorah!!! 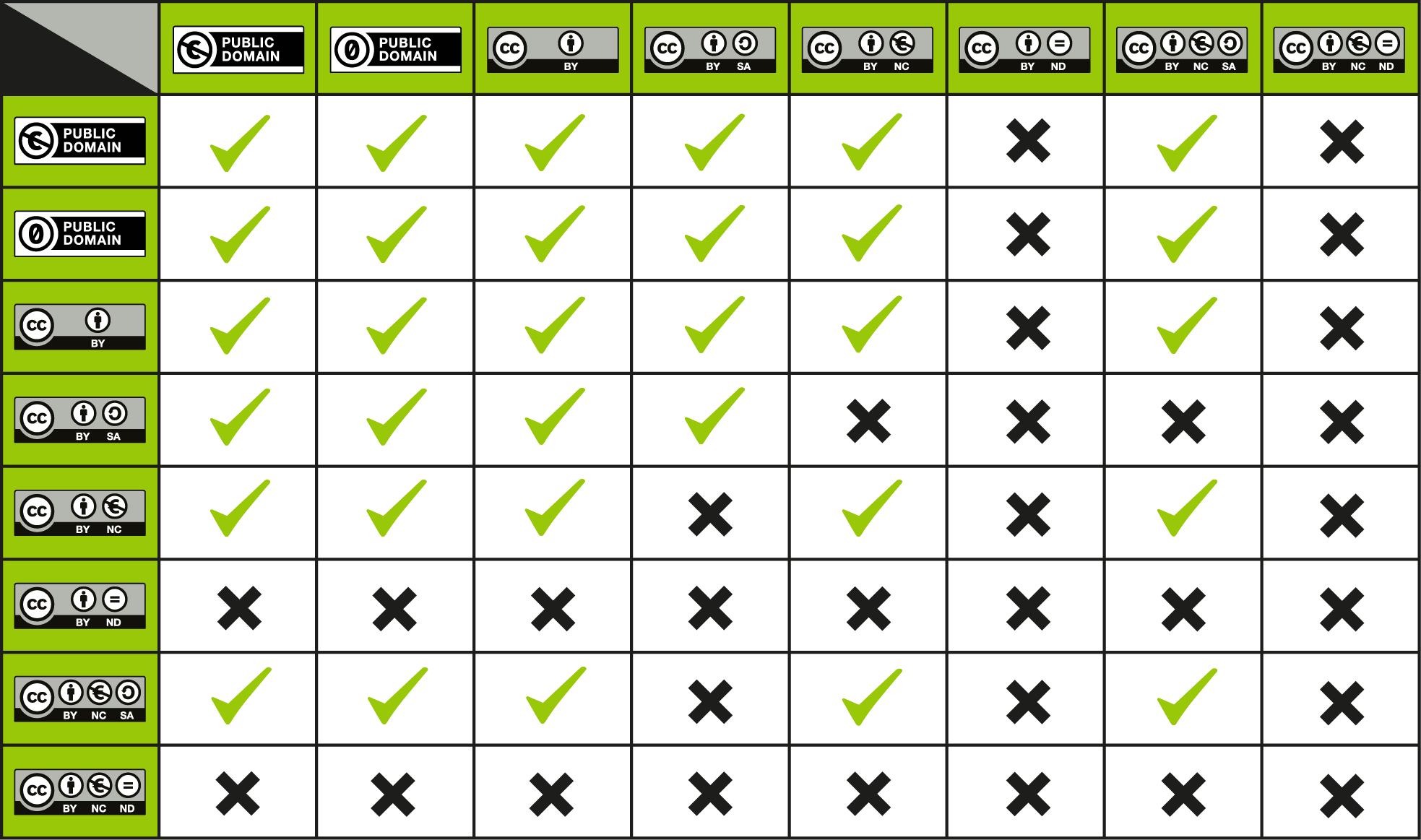{kind=link}